RNN, LSTN 부터 자연어를 이해하기 시작하는 수준이 되었다.
RNN(순환신경망)은 과거의 입력으로 다음 내용을 예측하는 것
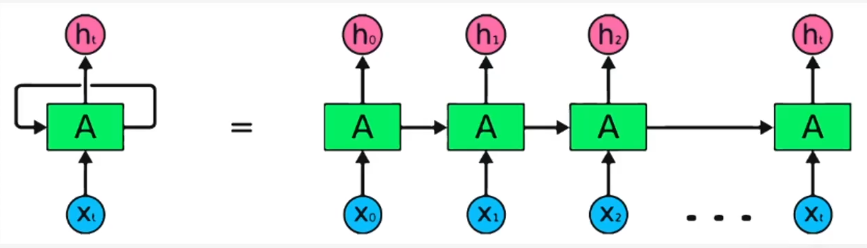
오늘 입력에 어제 입력값도 같이 받는다. 이런식으로 데이터를 연속으로 넣어서 처리한다.
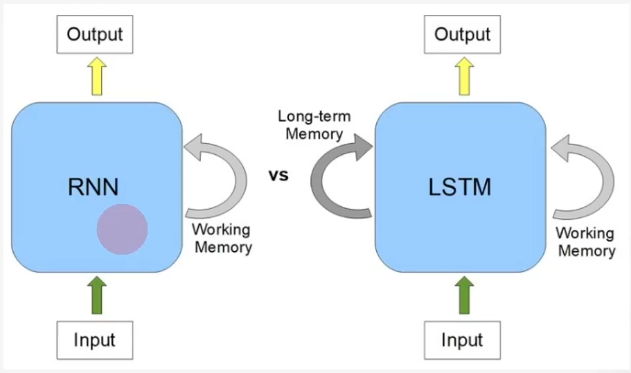
LSTM 은 RNN의 문제를 해결.
RNN은 이전걸 기억해도 메모리에 한계가 있다.
long-term 메모리를 추가로 가지고 넣는것이 LSTM
트랜스포머는 단어 사이의 관계를 나타낸다.
인코더와 디코더
인코더는 문장을 고정된 길이의 벡터로 변환한다.
결론적으로 보면 문장이 들어오면 그 내용을 하나의 컨텍스트 벡터로 변환하는 것이다.
디코더는 이 컨텍스트 벡터를 받아서 출력 문장을 만들어 낸다.

인코더는 임베딩 과정을 한다.
임베딩은 아래 같다
def encode(input_sequence, embedding_matrix):
"""
입력 시퀀스를 컨텍스트 벡터로 인코딩하는 간소화된 함수입니다.
Args:
- input_sequence: 문장 내 단어들을 대표하는 정수의 리스트입니다.
- embedding_matrix: 단어 인덱스를 임베딩으로 변환하는 행렬입니다.
Returns:
입력 시퀀스 전체의 정보를 담은 단일 벡터를 반환합니다.
"""
# 단계 1: 단어 임베딩
# 입력된 각 단어를 고차원 벡터로 변환합니다.
embedded_sequence = [embedding_matrix[word] for word in input_sequence]
# 단계 2: Self-Attention : 단어들 사이의 상호작용을 계산합니다.
# 여기서는 모든 임베딩의 합을 임베딩의 수로 나누어 평균 벡터를 생성합니다.
attention_output = sum(embedded_sequence) / len(embedded_sequence)
# 단계 3: 포지션-와이즈 피드포워드 네트워크 :각 위치의 출력을 독립적으로 변환하는 과정을 단순화
# 여기서는 결과 벡터에 고정된 스칼라(1.5)를 곱합니다.
context_vector = attention_output * 1.5
return context_vector
# 예시 사용법:
input_sequence = [3, 14, 15, 92] # 단어 인덱스로 표현된 예제 문장
embedding_matrix = {
3: [0.1, 0.2],
14: [0.4, 0.5],
15: [0.6, 0.7],
92: [0.8, 0.9]
} # 간소화된 임베딩 행렬
context_vector = encode(input_sequence, embedding_matrix)
print("컨텍스트 벡터:", context_vector)
디코더는 아래와 같다
def simple_decoder(encoded_context, start_token, vocabulary, embedding_matrix, max_length):
"""
간소화된 디코더 함수. 인코딩된 컨텍스트 벡터를 사용하여 새로운 시퀀스를 생성합니다.
Args:
- encoded_context: 인코더로부터 넘어온 컨텍스트 벡터.
- start_token: 출력 시퀀스 생성을 시작하는 토큰.
- vocabulary: 가능한 모든 출력 토큰의 집합.
- embedding_matrix: 단어 임베딩을 위한 행렬.
- max_length: 생성할 시퀀스의 최대 길이.
Returns:
생성된 시퀀스의 단어 인덱스 리스트.
"""
output_sequence = [start_token]
for _ in range(max_length):
# 현재까지의 출력 시퀀스를 기반으로 다음 토큰 예측 (단순화된 예시로, 무작위 선택을 사용)
next_token = random.choice(list(vocabulary))
output_sequence.append(next_token)
# 'end' 토큰을 만나면 시퀀스 생성 종료
if next_token == 'end':
break
return output_sequence
# 예시 사용
encoded_context = [0.5, -0.1] # 인코더로부터의 컨텍스트 벡터 예시
start_token = 'hello' # 시퀀스 생성을 위한 시작 토큰
vocabulary = {'start', 'hello', 'world', 'end'} # 가능한 단어 집합
max_length = 5 # 생성할 시퀀스의 최대 길이
# 디코더 실행
output_sequence = simple_decoder(encoded_context, start_token, vocabulary, embedding_matrix, max_length)
print("Generated Sequence:", output_sequence)
트랜스포머는 위치에 대한 건 신경쓰지 않기에 위치 인코딩 과정이 필요하다.
'openai' 카테고리의 다른 글
| 임베딩, 벡터 (0) | 2024.11.08 |
|---|---|
| pytorch로 gpu 사용하기 (0) | 2024.08.28 |
| 아마존 AWS에 내 챗봇 올리기 (0) | 2024.08.26 |
| 카카오 플러스 친구에 내 챗봇 올리 (0) | 2024.08.26 |
| Bing api key를 받아서 검색하기 (0) | 2024.08.18 |


